
In today’s data-driven world, machine learning (ML) and artificial intelligence (AI) have become integral components of many organizations’ strategies. Businesses rely on ML models for decision-making, customer insights, and process optimization. However, developing and deploying ML models at scale is not without its challenges. This is where MLOps pipelines come into play, serving as the bridge between the world of machine learning and the realm of operations.
Understanding MLOps
MLOps, short for Machine Learning Operations, is a practice that combines DevOps principles with ML processes to streamline the development and deployment of ML models. It aims to eliminate the silos between data scientists, machine learning engineers, and operations teams, creating a unified approach to building and managing ML applications. At the heart of MLOps lies the MLOps pipeline, a critical component that facilitates collaboration, automation, and reproducibility in the ML lifecycle.
The Anatomy of an MLOps Pipeline
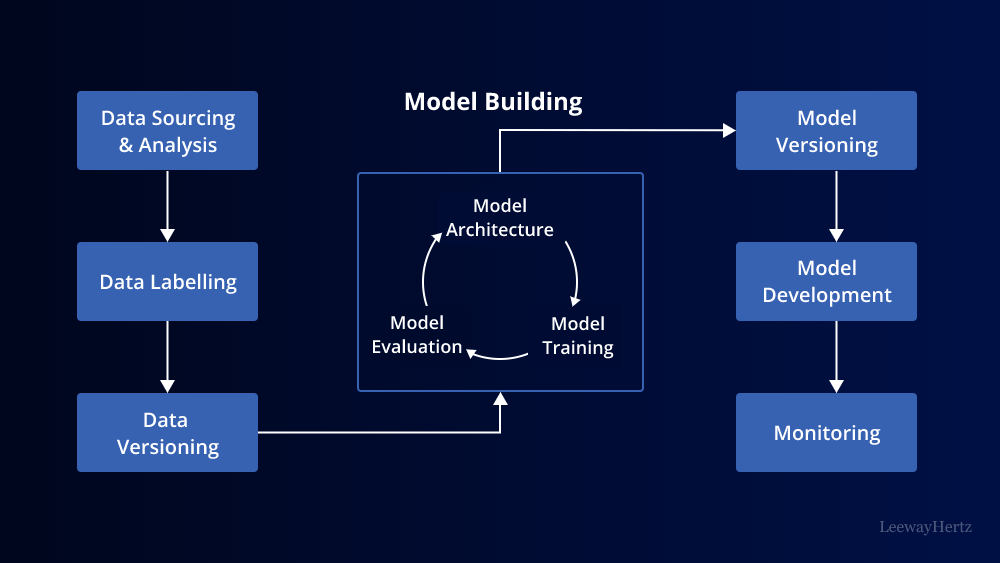
An MLOps pipeline is a series of interconnected steps that guide the ML model from its conception to production deployment. While the specific components of an MLOps pipeline can vary depending on the organization’s needs and tools used, a typical pipeline consists of the following key stages:
- Data Collection and Preparation: The journey begins with data collection, where raw data is gathered from various sources. Data preprocessing and cleaning follow this step to ensure the data is of high quality and ready for model training.
- Feature Engineering: Feature engineering involves selecting, transforming, and creating features (input variables) that the ML model will use to make predictions. This step can significantly impact the model’s performance.
- Model Development: Data scientists and machine learning engineers create and fine-tune ML models using the prepared data. This stage often involves experimenting with different algorithms and hyperparameters to achieve the best results.
- Validation and Testing: Models are evaluated rigorously to ensure they meet performance criteria. This includes cross-validation, testing against holdout datasets, and assessing metrics like accuracy, precision, recall, and F1 score.
- Model Deployment: Once a model passes validation and testing, it’s time to deploy it into production. This stage involves containerization, setting up APIs, and integration with existing systems.
- Monitoring and Maintenance: Post-deployment, continuous monitoring ensures that the model performs as expected. Monitoring tools track model drift, data quality, and overall system health. Regular maintenance may involve retraining models with new data or fine-tuning them to adapt to changing conditions.
- Feedback Loop: The feedback loop connects operations back to the data science and development teams. It captures insights from the production environment and informs further improvements in the model and pipeline.
Benefits of MLOps Pipelines
Implementing MLOps pipelines offers numerous advantages for organizations aiming to scale their ML initiatives:
- Efficiency: MLOps automates repetitive tasks, reducing the time and effort required to move from model development to deployment. This efficiency allows teams to iterate quickly and experiment with different models.
- Reproducibility: MLOps pipelines create a well-documented and reproducible workflow. This ensures that anyone can reproduce the model development process, which is crucial for auditing, compliance, and collaboration.
- Collaboration: Collaboration between data scientists, machine learning engineers, and operations teams is streamlined, fostering a culture of teamwork and knowledge sharing. Teams can work together seamlessly to deliver high-quality ML applications.
- Scalability: MLOps pipelines are designed to handle the scaling demands of ML applications. As data volumes and user loads increase, the pipeline can adapt to ensure the model’s performance and reliability.
- Risk Management: Continuous monitoring and feedback loops help detect and address issues early, reducing the risks associated with deploying and maintaining ML models in production.
Challenges in Implementing MLOps Pipelines
While MLOps pipelines offer many benefits, their implementation can be challenging:
- Complexity: Building and managing MLOps pipelines requires expertise in both machine learning and DevOps, making it a complex endeavor.
- Tooling: Selecting the right tools and technologies for an MLOps pipeline can be overwhelming, as there is a wide array of options available, each with its own strengths and weaknesses.
- Cultural Shift: MLOps often requires a cultural shift within organizations. Teams accustomed to traditional development practices may need time to adapt to the collaborative and iterative nature of MLOps.
- Data Governance: Ensuring data privacy and compliance with regulations can be complex, especially when dealing with sensitive data in ML projects.
Conclusion
MLOps pipelines are a critical component of the modern data-driven organization. They provide the means to efficiently develop, deploy, and manage ML models at scale, offering numerous benefits while also presenting challenges that need to be overcome. As organizations continue to invest in machine learning and artificial intelligence, mastering MLOps becomes increasingly essential for staying competitive and achieving success in the digital age. By understanding the anatomy of MLOps pipelines and embracing the MLOps mindset, organizations can harness the power of machine learning while maintaining operational excellence.
